
Journal of Geodesy and Geoinformation Science ›› 2023, Vol. 6 ›› Issue (4): 27-39.doi: 10.11947/j.JGGS.2023.0403
Previous Articles Next Articles
Mengyu WANG1,2,3,4( ), Zhiyuan YAN1,4(), Yingchao FENG1,4, Wenhui DIAO1,4, Xian SUN1,2,3,4
), Zhiyuan YAN1,4(), Yingchao FENG1,4, Wenhui DIAO1,4, Xian SUN1,2,3,4
Received:2023-07-26
Accepted:2023-11-06
Online:2023-12-20
Published:2024-02-06
Contact:
Zhiyuan YAN
E-mail:wangmentyu22@mails.ucas.ac.cn;ganzy@aircas.ac.cn
About author:Mengyu WANG E-mail: wangmentyu22@mails.ucas.ac.cn
Supported by:Mengyu WANG, Zhiyuan YAN, Yingchao FENG, Wenhui DIAO, Xian SUN. Multi-task Learning of Semantic Segmentation and Height Estimation for Multi-modal Remote Sensing Images[J]. Journal of Geodesy and Geoinformation Science, 2023, 6(4): 27-39.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks

Fig.1
Multi-modal remote sensing images and their characteristics"
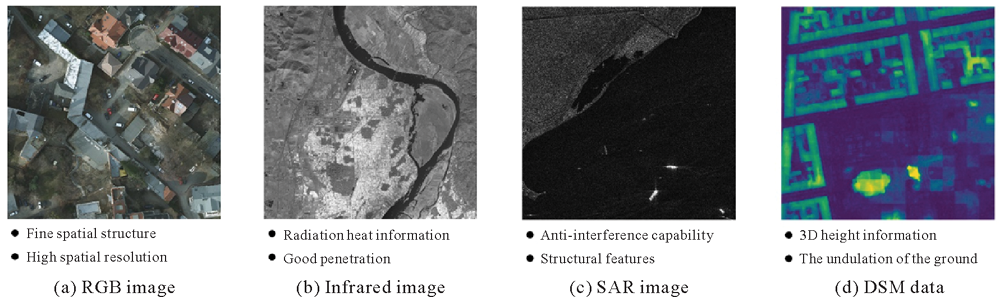
Fig.2
The pipeline of the MM_MT framework (The encoder is responsible for processing multi-modal input, including shared ResNet50 to encode RGB modality, and a separate ResNet18 to encode IR modality. Then, the SS and HE decoders aggregate the contextual features using PPM to predict semantic label maps and height maps, respectively)"

Tab.1
Feature extraction network based on ResNet"
| Layer name | Output size | Stride | Dilated rate |
|---|---|---|---|
| Conv1_1 | 256×256(1/2) | 2 | - |
| Conv1_2 | 256×256(1/2) | 1 | - |
| Conv1_3 | 256×256(1/2) | 1 | - |
| Layer1 | 128×128(1/4) | 1 | 1 |
| Layer2 | 64×64(1/8) | 2 | 1 |
| Layer3 | 64×64(1/8) | 1 | 2 |
| Layer4 | 64×64(1/8) | 1 | 4 |
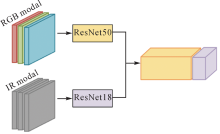
Fig.3
Feature fusion network (We convert the single-band IR image into a three-channel format by replicating it; then we employ a feature channel splicing method for feature-level fusion)"
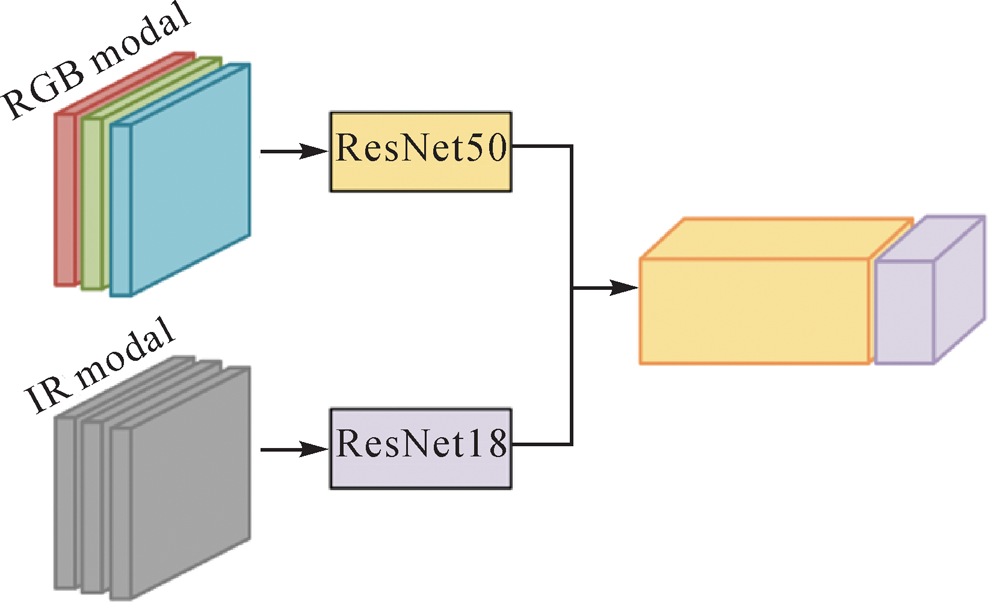
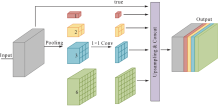
Fig.4
The structure of PPM (First, four pooling scale divides the input features into different regions, enabling the module to capture contextual information at various scales. The pooling process does not alter the feature dimension. Next, 1×1 convolution is used to reduce the feature dimension of each scale which is one-fourth of the input PPM feature dimension. Finally, These features are upsampled then concatenated)"
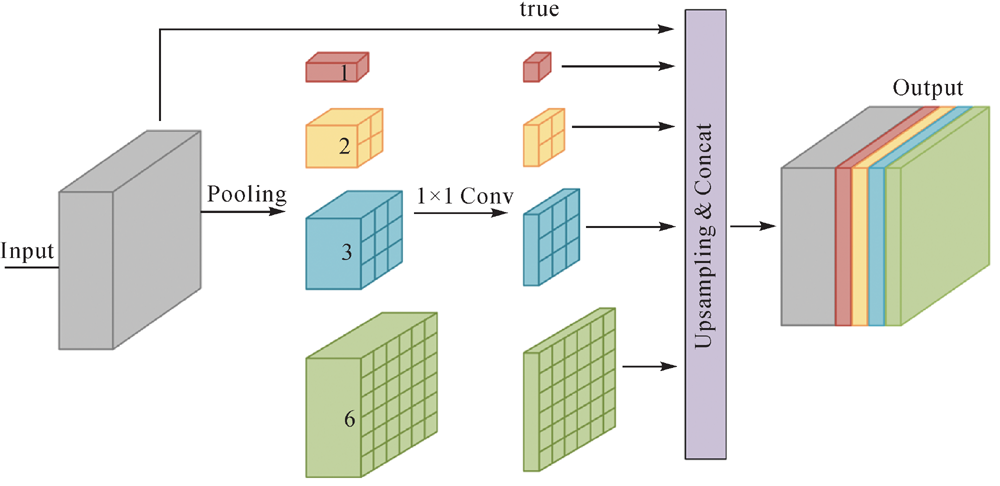

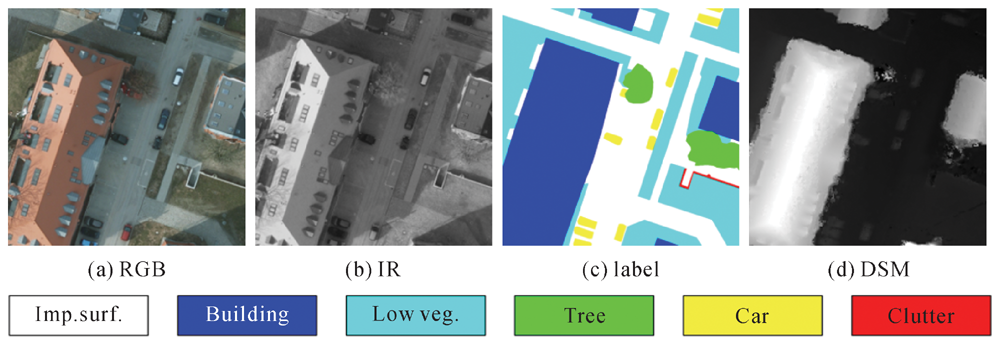
Fig.5
Potsdam dataset"
Tab.2
Comparison of CMFF in semantic segmentation (%)"
| Method | mIoU | OA |
|---|---|---|
| Baseline(SM_SS) | 81.84 | 87.80 |
| +CMFF(MM_SS) | 82.34 | 88.30 |
Tab.3
Comparison of CMFF in height estimation"
| Method | Rel | Rmse | δ1/(%) |
|---|---|---|---|
| Baseline(SM_HE) | 0.0993 | 1.108 | 96.15 |
| +CMFF(MM_HE) | 0.1094 | 1.232 | 94.42 |
Tab.4
Comparison of performance and efficiency using JSSHE"
| Method | mIoU /(%) | δ1 /(%) | Training speed /(s/iter) | Model size /MB |
|---|---|---|---|---|
| SM_SS | 81.84 | - | 0.48 | 267.18 |
| SM_HE | - | 96.15 | 0.48 | 267.17 |
| +JSSHE (SM_MT) | 79.09 | 94.33 | 0.72 | 399.26 |
Tab.5
Performance comparison of different loss weights between two tasks in SM_MT"
| Task/α | 0.5 | 1 | 1.5 |
|---|---|---|---|
| SS(mIoU) | 79.23% | 79.09% | 78.42% |
| HE(Rel) | 0.1168 | 0.1094 | 0.1135 |
Tab.6
Quantitative performance of SS, HE, and MM_MT on the Potsdam test set"
| Task | Method | mIoU/(%) | OA/(%) | Rel | Rmse | δ1/(%) | Model Size/MB | Running time/ (images/s) |
|---|---|---|---|---|---|---|---|---|
| SS | FCN(2015)[ | 78.34 | 85.59 | - | - | - | 378.2 | 25 |
| UNet(2015)[ | 82.89 | 89.13 | - | - | - | 376.9 | 20 | |
| S-RA-FCN(2020)[ | - | 88.59 | - | - | - | - | - | |
| SCAttNet(2021)[ | 77.94 | 7.97 | - | - | - | - | - | |
| HE | D3Net(2018)[ | - | - | 0.0902 | 1.218 | 95.15 | 426.0 | 11 |
| HEED(2019)[ | - | - | 0.1048 | 1.430 | 91.91 | 234.4 | 28 | |
| PLNet(2022)[ | - | - | - | 2.356 | - | 241.3 | - | |
| Two tasks | MM_MT | 83.02 | 88.88% | 0.1076 | 1.194 | 95.26 | 537.7 | 32 |
Tab.7
The comparison of multi-task learning performance and efficiency"
| Method | mIoU/(%) | OA/(%) | Rel | Rmse | δ1/(%) | Training speed/( s/iter) | Model size/MB | Running time/ ( images/s) |
|---|---|---|---|---|---|---|---|---|
| MM_SS | 82.34 | 88.30 | - | - | - | 0.66 | 405.63 | 20 |
| SM_HE | - | - | 0.0993 | 1.108 | 96.15 | 0.48 | 267.17 | 26 |
| MM_MT | 83.02 | 88.88 | 0.1076 | 1.194 | 95.26 | 0.91 | 537.71 | 32 |
Tab.8
The comparison of multi-modal fusion performance"
| Task | Method | mIoU/(%) | OA/(%) | Rel | Rmse | δ1/(%) | |
|---|---|---|---|---|---|---|---|
| Semantic segmentation | SM_SS | 81.84 | 87.80 | - | - | - | |
| Image-level fusion | 81.53 | 87.61 | - | - | - | ||
| Feature-level fusion (MM_SS) | 82.34 | 88.30 | - | - | - | ||
| Height estimation | SM_HE | - | - | 0.0993 | 1.108 | 96.15 | |
| Image-level fusion | - | - | 0.1211 | 1.462 | 91.68 | ||
| Feature-level fusion (MM_HE) | - | - | 0.1094 | 1.232 | 94.42 | ||
| Two tasks | SM_MT | 79.09 | 86.92 | 0.1094 | 0.0632 | 94.33 | |
| Image-level fusion | 82.57 | 88.45 | 0.1079 | 0.0615 | 94.71 | ||
| Feature-level fusion (MM_MT) | 83.02 | 88.88 | 0.1076 | 0.0597 | 95.26 |

Fig.6
The visualization of semantic segmentation"
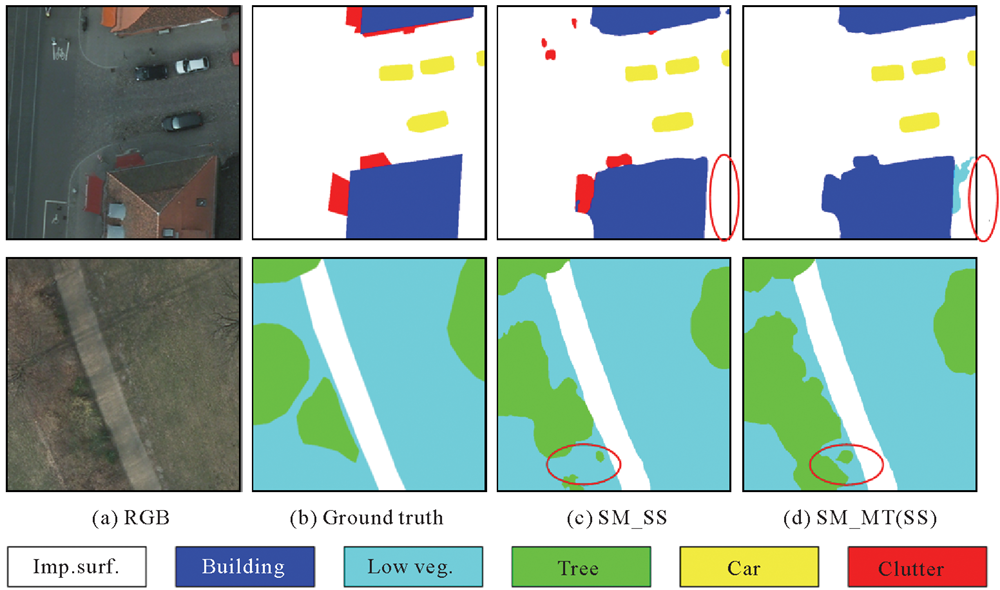

Fig.7
The visualization of height estimation"


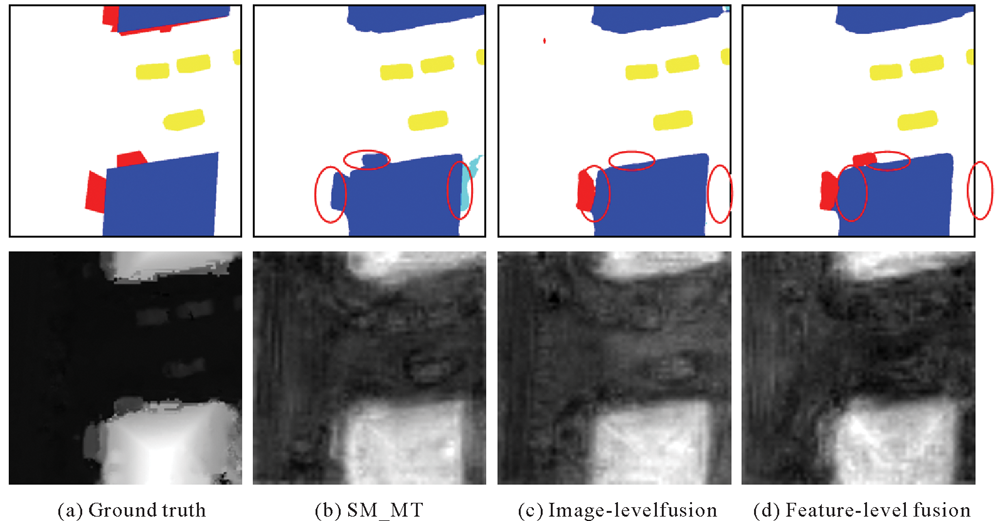
Fig.8
The visualization of multi-modal fusion"
| [1] | ZHU Xiaoxiang, TUIA Devis, MOU Lichao, et al. Deep learning in remote sensing: a comprehensive review and list of resources[J]. IEEE Geoscience and Remote Sensing Magazine, 2017, 5(4): 8-36. |
| [2] | MENG Xiaoliang, YANG Yuechi, WANG Libo, et al. Class-guided swin transformer for semantic segmentation of remote sensing imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 1-56517505. |
| [3] |
SUN Long, WU Tao, Sun Guangcai, et al. Object detection research of SAR image using improved faster region-based convolutional neural network[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 18-28.
doi: 10.11947/j.JGGS.2020.0302 |
| [4] | MOU Lichao, ZHU Xiaoxiang. IM2HEIGHT: height estimation from single monocular imagery via fully residual convolutional-deconvolutional network[M/OL]. [2023-06-26]. http://arXiv.org/abs/:1802.10249, 2018. |
| [5] |
HUANG Zhongling, DATCU Mihai, PAN Zongxu, et al. Deep SAR-Net: learning objects from signals[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 161: 179-193.
doi: 10.1016/j.isprsjprs.2020.01.016 |
| [6] |
YAN Zhiyuan, WANG Peijin, XU Feng, et al. AIR-PV: a benchmark dataset for photovoltaic panel extraction in optical remote sensing imagery[J]. Science China Information Sciences, 2023, 66(4): 140307.
doi: 10.1007/s11432-022-3663-1 |
| [7] |
LI Shutao, LI Congyu, KANG Xudong. Development status and future prospects of multi-source remote sensing image fusion[J]. National Remote Sensing Bulletin, 2021, 25(1): 148-166.
doi: 10.11834/jrs.20210259 |
| [8] | ZHANG Jiaqing, LEI Jie, XIE Weiying, et al. SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-155605415. |
| [9] | ZHENG Aihua, HE Jinbo, WANG Ming, et al. Category-wise fusion and enhancement learning for multimodal remote sensing image semantic segmentation[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-124416212. |
| [10] |
LI Xue, ZHANG Guo, CUI Hao, et al. MCANet: a joint semantic segmentation framework of optical and SAR images for land use classification[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 106: 102638.
doi: 10.1016/j.jag.2021.102638 |
| [11] | LIU Wenjie, SUN Xian, ZHANG Wenkai, et al. Associatively segmenting semantics and estimating height from monocular remote-sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-175624317. |
| [12] | ZHU Panpan, LI Shuaipeng, ZHANG Liqiang, et al. Multitask learning-based building extraction from high-resolution remote sensing images[J]. Journal of Geo-Information Science, 2021, 23(3): 514-523. |
| [13] |
LIU Anan, SU Yuting, NIE Weizhi, et al. Hierarchical clustering multi-task learning for joint human action grouping and recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(1): 102-114.
pmid: 26955018 |
| [14] |
LIU Anan, XU Ning, NIE Weizhi, et al. Multi-domain and multi-task learning for human action recognition[J]. IEEE Transactions on Image Processing, 2019, 28(2): 853-867.
doi: 10.1109/TIP.2018.2872879 |
| [15] | RUDER S. An overview of multi-task learning in deep neural networks[M/OL]. [2023-06-26]. http://arXiv.org/abs/:1706.05098, 2017. |
| [16] |
FENG Yingchao, SUN Xian, DIAO Wenhui, et al. Height aware understanding of remote sensing images based on cross-task interaction[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2023, 195: 233-249.
doi: 10.1016/j.isprsjprs.2022.11.014 |
| [17] |
ZUO Zongcheng, ZHANG Wen, ZHANG Dongying. A remote sensing image semantic segmentation method by combining deformable convolution with conditional random fields[J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 39-49.
doi: 10.11947/j.JGGS.2020.0304 |
| [18] | RONNEBERGER O, FISCHER P, BROX T. U-Net:convolutional networks for biomedical image segmentation[C]// Proceedings of the 18th International Conference on In Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015: 18th International Conference. Munich: Springer, 2015: 234-241. |
| [19] | ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 2881-2890. |
| [20] |
DIAKOGIANNIS F I, WALDNER F, CACCETTA P, et al. ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162: 94-114.
doi: 10.1016/j.isprsjprs.2020.01.013 |
| [21] | FENG Yingchao, DIAO Wenhui, SUN Xian, et al. NPALOSS: neighboring pixel affinity loss for semantic segmentation in high-resolution aerial imagery[C]// Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences. [S.l.]: ISPRS, 2020: 475-482. |
| [22] | EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems Advances in Neural Information Processing Systems. Montreal: MIT Press, 2014(27): 2366-2374. |
| [23] |
AO Ying, LI Penglong, WEN Li, et al. Fully convolutional networks for street furniture identification in panorama images[J]. Journal of Geodesy and Geoinformation Science, 2022, 5(4): 59-71.
doi: 10.11947/j.JGGS.2022.0406 |
| [24] |
MOU Lichao, HUA Yuansheng, ZHU Xiaoxiang. Relation matters: relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2020, 58(11): 7557-7569.
doi: 10.1109/TGRS.36 |
| [25] |
LI Haifeng, QIU Kaijian, CHEN Li, et al. SCAttNet: semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2021, 18(5):905-909.
doi: 10.1109/LGRS.2020.2988294 |
| [26] |
LI Jiaxin, HONG Danfeng, GAO Lianru, et al. Deep learning in multimodal remote sensing data fusion: a comprehensive review[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 112: 102926.
doi: 10.1016/j.jag.2022.102926 |
| [27] | WU Xin, HONG Danfeng, CHANUSSOT J. Convolutional neural networks for multimodal remote sensing data classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 60: 1-105517010. |
| [28] |
SUN Xian, TIAN Yu, LU Wanxuan, et al. From single-to multi-modal remote sensing imagery interpretation: a survey and taxonomy[J]. Science China Information Sciences, 2023, 66(4): 140301.
doi: 10.1007/s11432-022-3588-0 |
| [29] | CHEN Kaiqiang, FU Kun, GAO Xin, et al. Effective fusion of multi-modal data with group convolutions for semantic segmentation of aerial imagery[C]//Proceedings of 2019 IEEE International Geoscience and Remote Sensing Symposium. Yokohama: IEEE, 2019: 3911-3914. |
| [30] | XING Siyuan, DONG Qiulei, HU Zhanyi. Gated feature aggregation for height estimation from single aerial images[J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19:1-5. |
| [31] | SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: a remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-225612822. |
| [32] | VANDENHENDE S, GEORGOULIS S, VAN GANSBEKE W, et al. Multi-task learning for dense prediction tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3614-3633. |
| [33] | KOKKINOS I. UberNet: training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 6129-6138. |
| [34] | SRIVASTAVA S, VOLPI M, TUIA D. Joint height estimation and semantic labeling of monocular aerial images with CNNS[C]//Proceedings of 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Fort Worth, TX: IEEE, 2017: 5173-5176. |
| [35] |
WANG Yufeng, DING Wenrui, ZHANG Ruiqian, et al. Boundary-aware multitask learning for remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 951-963.
doi: 10.1109/JSTARS.4609443 |
| [36] | SONG Weiwei, DAI Yong, GAO Zhi, et al. Hashing-based deep metric learning for the classification of hyperspectral and LiDAR data[J], IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:1-13. |
| [37] | SUN Xian, WANG Peijin, LU Wanxuan, et al. RingMo: a remote sensing foundation model with masked image modeling[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 1-22. |
| [38] | VANDENHENDE S, GEORGOULIS S, VAN GANSBEKE W, et al. Multi-task learning for dense prediction tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3614-3633. |
| [39] | KOKKINOS I. Ubernet: training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA:IEEE, 2017: 6129-6138. |
| [40] | SRIVASTAVA S, VOLPI M, TUIA D. Joint height estimation and semantic labeling of monocular aerial images with CNNS[C]//Proceedings of 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Fort Worth, TX, USA: IEEE, 2017: 5173-5176. |
| [41] |
WANG Yufeng, DING Wenrui, ZHANG Ruiqian, et al. Boundary-aware multitask learning for remote sensing imagery[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 951-963.
doi: 10.1109/JSTARS.4609443 |
| [42] | GAO Zhi, SUN Wenbo, LU Yao, et al. Joint learning of semantic segmentation and height estimation for remote sensing image leveraging contrastive learning[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61:1-15. |
| [43] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 770-778. |
| [44] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
doi: 10.1109/TPAMI.2017.2699184 |
| [45] | ISPRS. 2D Semantic Labeling Contest-Potsdam. [EB/OL]. [2023-09-01]. https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx. |
| [1] | Min WANG, Peidong WANG. CFM-UNet: A Joint CNN and Transformer Network via Cross Feature Modulation for Remote Sensing Images Segmentation [J]. Journal of Geodesy and Geoinformation Science, 2023, 6(4): 40-47. |
| [2] | Tong ZHENG,Peng LEI,Jun WANG. A Hybrid Features Based Detection Method for Inshore Ship Targets in SAR Imagery [J]. Journal of Geodesy and Geoinformation Science, 2023, 6(1): 95-107. |
| [3] | Qiuyu YAN, Wufan ZHAO, Xiao HUANG, Xianwei LYU. Automated Delineation of Smallholder Farm Fields Using Fully Convolutional Networks and Generative Adversarial Networks [J]. Journal of Geodesy and Geoinformation Science, 2022, 5(4): 10-22. |
| [4] | Junxiang ZHANG, Peiran LI, Haoran ZHANG, Xuan SONG. Investigation on the Relationship between Population Density and Satellite Image Features—a Deep Learning Based Approach [J]. Journal of Geodesy and Geoinformation Science, 2022, 5(4): 50-58. |
| [5] | Ying AO, Penglong LI, Li WEN, Tao ZHANG, Yanwen WANG. Fully Convolutional Networks for Street Furniture Identification in Panorama Images [J]. Journal of Geodesy and Geoinformation Science, 2022, 5(4): 59-71. |
| [6] | Yanjun WANG,Shaochun LI,Mengjie WANG,Yunhao LIN. A Simple Deep Learning Network for Classification of 3D Mobile LiDAR Point Clouds [J]. Journal of Geodesy and Geoinformation Science, 2021, 4(3): 49-59. |
| [7] | Zongcheng ZUO, Wen ZHANG, Dongying ZHANG. A Remote Sensing Image Semantic Segmentation Method by Combining Deformable Convolution with Conditional Random Fields [J]. Journal of Geodesy and Geoinformation Science, 2020, 3(3): 39-49. |
| [8] | Hao HE,Shuyang WANG,Shicheng WANG,Dongfang YANG,Xing LIU. A Road Extraction Method for Remote Sensing Image Based on Encoder-Decoder Network [J]. Journal of Geodesy and Geoinformation Science, 2020, 3(2): 16-25. |
| [9] | Dazhao FAN,Yang DONG,Yongsheng ZHANG. Satellite Image Matching Method Based on Deep Convolutional Neural Network [J]. Journal of Geodesy and Geoinformation Science, 2019, 2(2): 90-100. |
| [10] | Jianya GONG,Shunping JI. Photogrammetry and Deep Learning [J]. Journal of Geodesy and Geoinformation Science, 2018, 1(1): 1-15. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||